For most of the artificial intelligence (AI) and deep learning era, making a machine learning model smarter meant making it bigger. More parameters, more layers, more capacity. The problem is that in a normal neural network, every parameter is used for every input. Double the size and you double the cost of running it, for every single token, every single time. That doesn’t scale forever.
Mixture of Experts (MoE) is the architecture that breaks this link between how big a model is and how expensive it is to run. The idea is to keep a large pool of small sub-networks called “experts,” but only switch on a small handful of them for any given input. The model can be enormous in total size while staying cheap to run, because it never uses all of itself at once.
That single trick is why MoE has gone from a niche research idea to the default design for many frontier AI models being built today. Below is how it actually works, how it differs from a standard transformer, and which well-known models are built on it.
The Mixture of Experts Architecture
An MoE layer is built from a small number of distinct components working together. The diagram below shows the full flow: a token enters at the top, the router decides which experts handle it, the chosen experts run, and their outputs are combined into the final result.
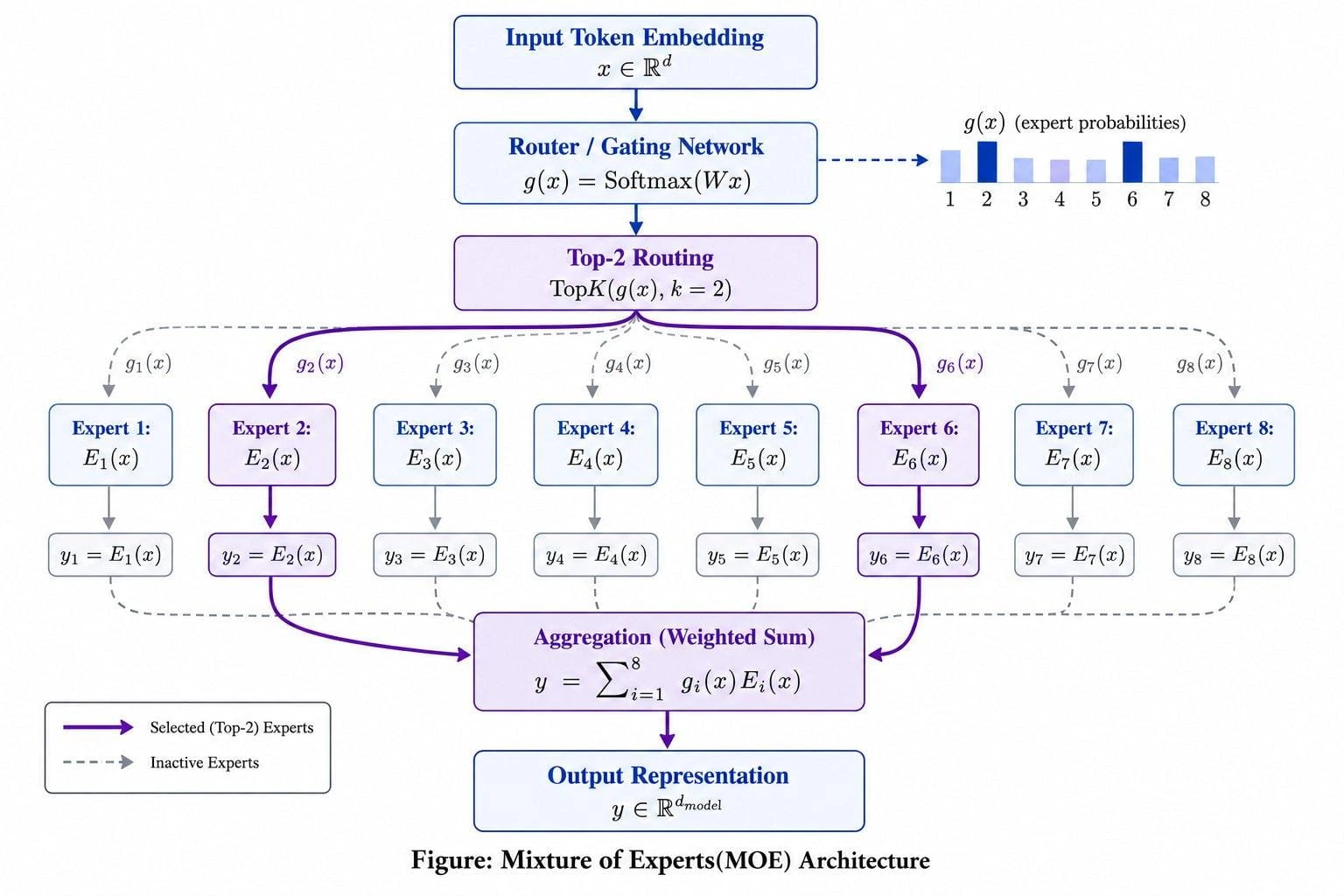
Here’s what each component does.
Input token. Everything starts with a single token representation x ∈ ℝd, the vector that flows into the MoE layer, exactly as it would flow into a normal feed-forward layer.
The experts. These are a set of smaller neural networks sitting side by side, typically feed-forward networks, the same kind of building block found throughout a transformer. You might have 8 of them (as in the diagram), or 64, or several hundred. Each one, written Ei(x), is free to specialize in handling certain kinds of input patterns.
The router (gating network). This is the decision-maker. It looks at the incoming token, scores every expert, and turns those scores into probabilities with a softmax. It’s usually just a small linear layer:
g(x) = softmax(Wg x)
The output g(x) is a set of weights, one per expert, that say how relevant each expert is for this particular token.
Top-k routing. Rather than use every expert, the layer keeps only the top k highest-scoring ones (in the diagram, k = 2, experts 2 and 6) and ignores the rest. This is the step that creates sparse activation: out of all the experts, only a tiny fraction fire for any given token. Everything else stays completely idle.
Aggregation (weighted sum). The selected experts run, and their outputs are blended together according to the router’s weights to produce the layer’s output:
y = ∑i ∈ Top-k gi(x) Ei(x)
Here Ei(x) is the output of expert i, and gi(x) is how strongly the router weights that expert. Because the sum runs only over the top k experts, only those few are actually computed; the rest contribute nothing and cost nothing.
Output. The aggregated result y is passed along to the next layer, just like the output of an ordinary feed-forward sublayer.
One thing worth clearing up: an “expert” here isn’t a specialist in the human sense. There’s no grammar expert or math expert sitting in the layer. They’re just sub-networks, and whatever each one ends up good at is usually some abstract statistical pattern that doesn’t line up with categories we’d recognize. The router isn’t sorting tokens by topic, it’s sorting them by whatever happens to help the MoE model predict better.
Why this matters: total vs. active parameters
Sparse activation is the whole point. A model can hold a massive number of total parameters while only “spending” a small number on any individual input. People describe this with two numbers: total parameters (everything the model contains) and active parameters (what actually runs per token). In Mixture of Experts models these are wildly different, and that gap is what lets the model be huge in capacity but cheap to run.
For teams building enterprise solutions, quality validation for AI assisted products is essential to verify that model outputs remain accurate, safe, and consistent despite the complexity introduced by expert routing and sparse activation.
At the same time, advances in MoE architectures are enabling more sophisticated AI augmented product designworkflows, helping organizations build intelligent products that can adapt to user behavior, automate decision-making, and deliver highly personalized experiences at scale.
One practical consequence worth knowing: sparsity saves you computation, not memory. All those experts still have to be loaded and stored somewhere, so an MoE model’s memory footprint reflects its total size even though its speed reflects its much smaller active size.
Common refinements
A few variations show up across modern MoE designs and are worth naming:
- Shared experts: Some architectures keep one or two experts that are always active for every token, alongside the routed ones. The shared expert captures common, general-purpose patterns so the routed experts are free to specialize, rather than each having to relearn the basics.
- Fine-grained experts (granularity): Instead of a few large experts, you can split the same parameter budget into many smaller ones and route to more of them. This gives the router more combinations to choose from and tends to improve specialization without changing the active compute much.
- Number of experts and k: Two separate dials control the architecture: N, the total number of experts (this drives total capacity), and k, how many are activated per token (this drives the per-token cost). You scale N up for more knowledge and keep k small for efficiency.
Keeping the experts balanced (load balancing)
Load balancing is the mechanism that forces the router to use all of its experts fairly evenly instead of overloading a few. It’s needed because, left alone, the router drifts toward sending most tokens to a small set of experts; the rest stay undertrained and the model wastes most of the capacity it was built for.
In practice it’s almost always done with an auxiliary loss. Alongside the model’s normal training objective (predicting the next token), you add a second penalty term that looks at how the tokens in each batch were spread across the experts and grows larger when that distribution is lopsided. Because this term is added to the main loss and trained with everything else, the router is continuously pushed toward spreading tokens out. Importantly, this only happens during training. At inference the router just routes, with no balancing term involved.
A second method, often used alongside the loss, is expert capacity: each expert is given a fixed limit on how many tokens it can accept per batch, and any tokens beyond that limit are dropped (they skip the experts and pass through unchanged via the residual connection). The cap stops a single expert from being swamped even when the router wants to hand it everything.
Some recent models go a different route. DeepSeek-V3, for instance, drops the auxiliary loss in favor of a bias-based scheme: a small bias is added to each expert’s routing score and adjusted up or down between training steps to even out the load, which avoids the slight quality hit an extra loss term can introduce.
How It Differs From a Standard Transformer Block
The figure below puts the two side by side. The only thing that changes is the feed-forward slot: a standard block runs one dense FFN on every token, while an MoE block puts a router and a pool of expert FFNs in that same slot and activates just the top few per token. Attention, residual connections, and normalization are identical in both.
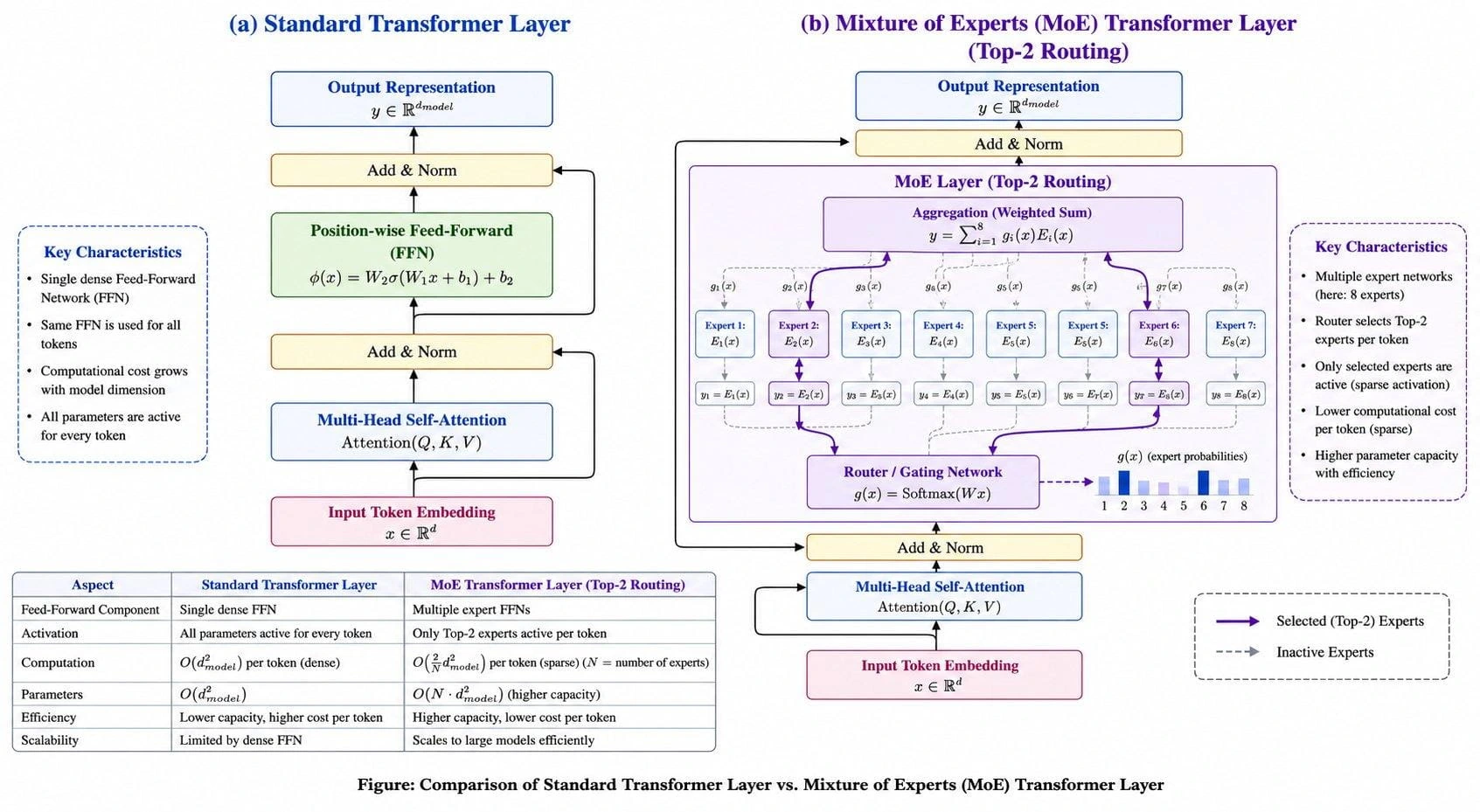
The thing the Mixture of Experts Transformer diagram doesn’t say out loud is why this is such a convenient change: because only the FFN sublayer is swapped and everything around it is untouched, you can take almost any existing transformer and “MoE-ify” it without redesigning the architecture.
That’s a big reason MoE spread so fast. It’s a drop-in replacement for a part the transformer already had, not a new kind of model.
Where MoE goes in a Vision Transformer
The same trick carries over to vision.
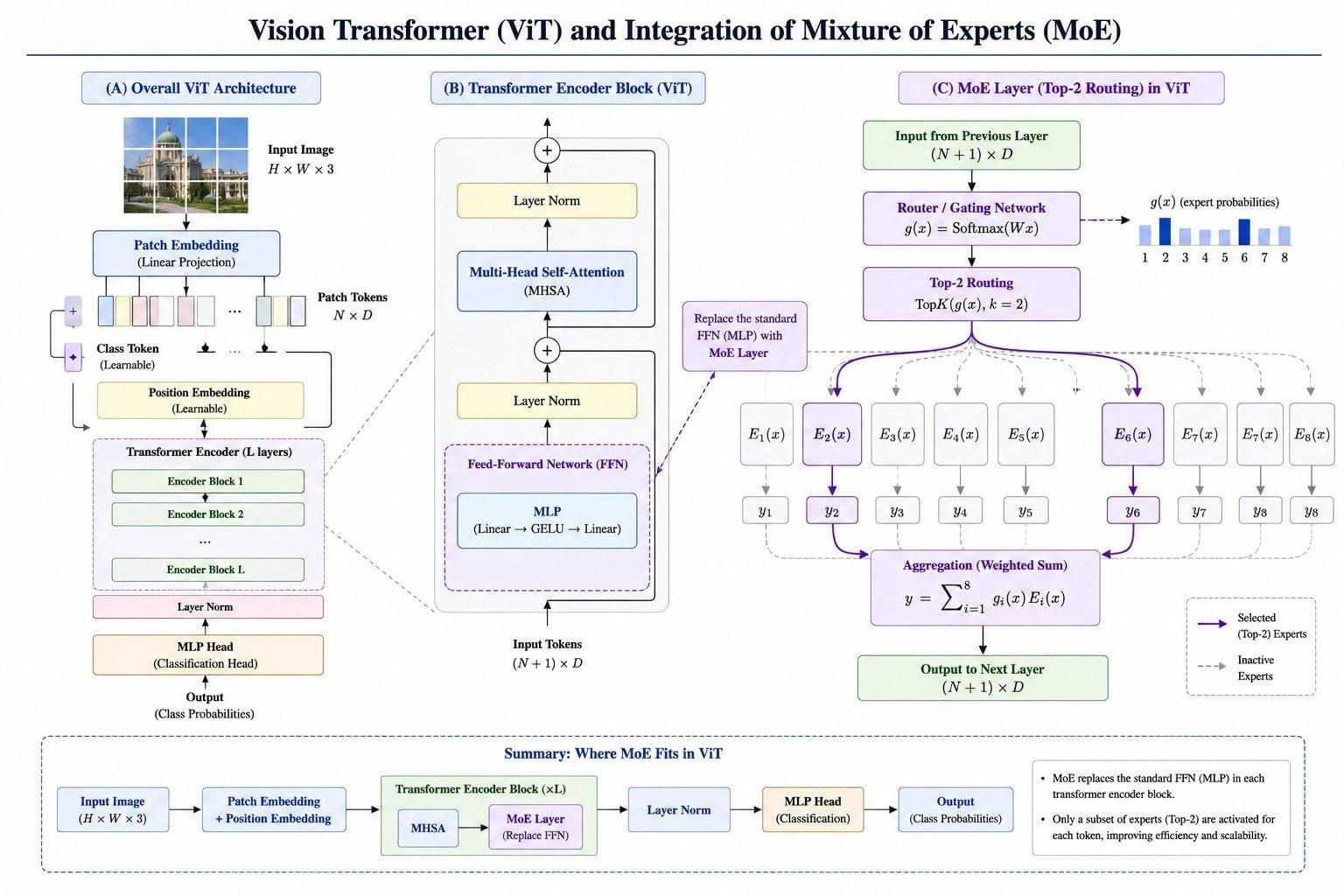
A Vision Transformer (ViT) splits an image into patches and runs them through transformer blocks, each with attention and an MLP (the vision world’s name for the feed-forward layer).
Vision MoE (V-MoE) replaces a subset of those dense MLP blocks with sparse MoE layers, where each expert is its own MLP and the router sends each image patch to a small number of them.
Everything else in the block stays shared, exactly as in the language case. In practice only some layers are converted (e.g. every other block), and routing uses a small k such as 1 or 2. So the slot that gets replaced is the same one as in a text model: the feed-forward network.
Famous Models That Use MoE
By 2026, MoE is the default design for serious models. In one recent roundup of leading open-source models, six of seven used it. The names that matter most right now:
- Qwen3 (Alibaba): a top open-weight MoE family. The flagship Qwen3 235B-A22B has 235B total parameters but only 22B active per token, under the permissive Apache 2.0 license.
- DeepSeek (V3 / V4): the family that made MoE famous. DeepSeek-V3 has 671B total parameters with just 37B active per token; the current DeepSeek V4 continues this with even better cost efficiency and very long context.
- Kimi K2 (Moonshot AI): an extreme example, a trillion-parameter MoE using 384 experts with only 8 selected per token, built for long-horizon agentic tasks.
- Llama 4 Scout (Meta): a 109B-total MoE with 17B active per token and a context window up to 10 million tokens.
- Gemma 4 (Google): proof MoE works small too, with about 25B total but only ~3.8B active per token, runnable locally.
The closed frontier follows the same pattern. GPT-4 was widely believed to use MoE (though OpenAI never confirmed it), and by 2026 nearly all frontier language models use some form of it.
Wrapping Up
So that’s the whole trick: keep a lot of experts around, but only run a few of them per token. You get the capacity of a much larger model without paying to run one, which is why so many recent models are built this way.
It isn’t free. You still have to fit every expert in memory even though most sit idle on any given token, and getting the router to spread work evenly takes real effort during training. For teams building state-of-the-art AI systems, though, that’s clearly a tradeoff worth making.
As a result, Mixture of Experts has become one of the defining architectural innovations in modern machine learning, and it’s a safe bet that MoE will remain a key part of frontier AI models for years to come.
