
Every piece of software needs to be updated and maintained regularly. Modern Rails deployment workflows continue to evolve, helping teams ship updates safely while minimizing downtime.
Features improve. Security vulnerabilities get patched. Underlying technology evolves. This is not a sign of poor quality, it is simply the reality of running any modern digital product.
But here is what most businesses do not realise: writing the new code is the straightforward part. The hard part is introducing that new code into a live system, one that real customers depend on, right now, without causing disruption.
Think of it like maintaining a busy airport. Planes cannot stop flying. Passengers cannot wait. Maintenance has to happen while everything else continues, and a mistake at the wrong moment can cascade in ways that were completely unpredictable in the calm of the workshop.
Most software problems that reach users are not caused by bad code. They are caused by the gap between a well-tested change and an unprepared production environment.
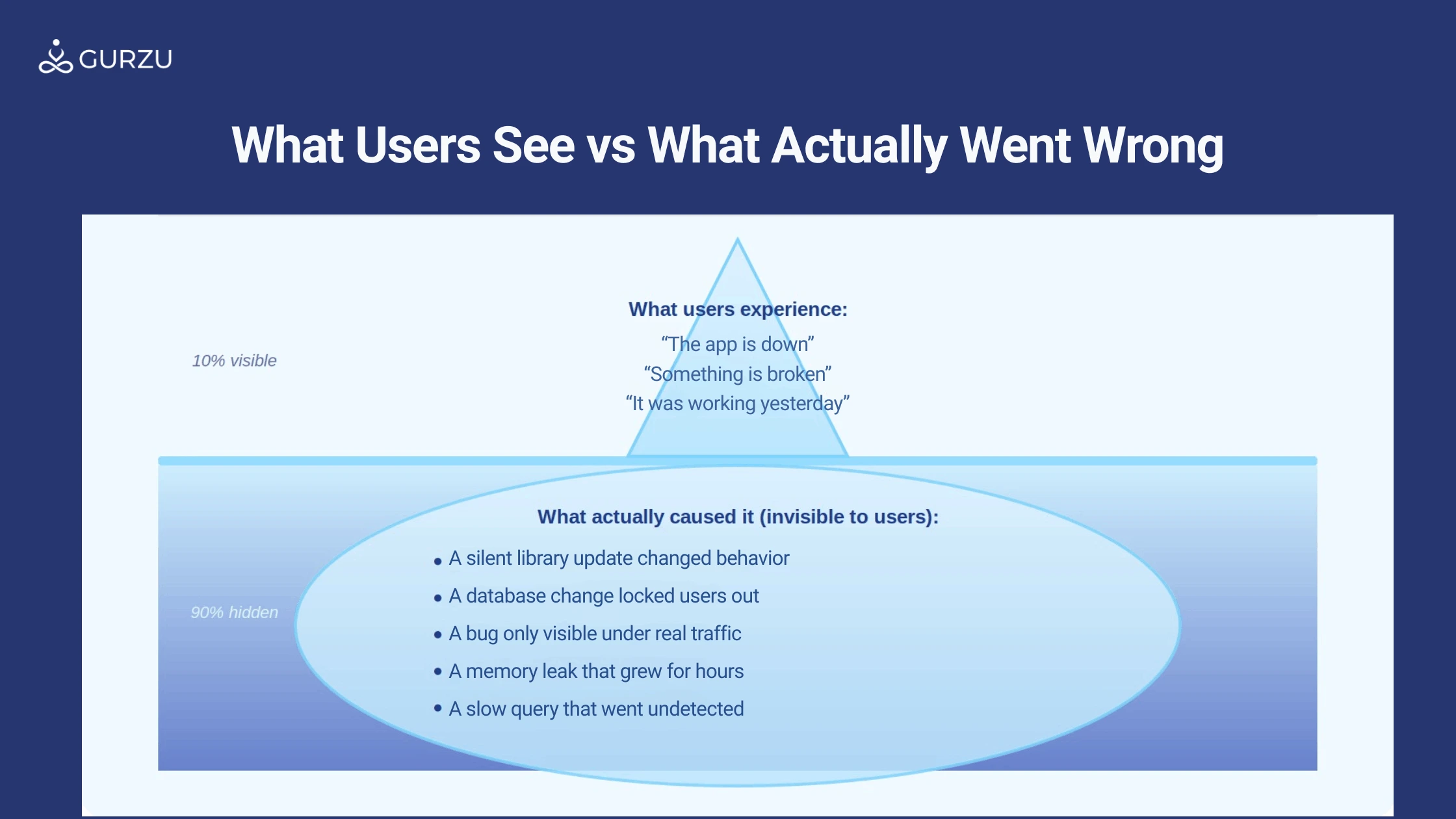
Figure 1: What users see vs. what actually caused the problem
The iceberg above illustrates the problem clearly. What a user experiences, a slow page, an error message, an outage, is just the visible tip. Underneath it are causes that were entirely preventable with the right process in place.
Gravity Of The Problem
When a software deployment goes wrong without a structured process in place, the costs accumulate quickly, and across multiple dimensions at the same time.
The question is never whether a deployment, maintenance or updates carries risk. They always do. The question is whether your team has the process to contain that risk before users feel it.
The costs are rarely just technical
- Direct revenue loss: if the application is unavailable, transactions cannot complete, bookings cannot be made, services cannot be delivered. For any business with meaningful digital revenue, even an hour of downtime has a real number attached to it.
- Engineering time: an unplanned production incident pulls your entire team into emergency mode. A three-hour incident typically consumes forty or more engineering hours across the people involved.
- Client trust: this is the hardest cost to quantify and the easiest to underestimate. A client who experiences an outage during a critical moment does not simply count the downtime , they reassess whether the platform is reliable enough to depend on.
- Compliance exposure: businesses operating under service level agreements may face breach conditions, financial penalties, and formal contract reviews.
Improvement of Process
Teams that achieve high reliability consistently rely on automation and disciplined processes. Effective CI/CD deployment automation reduces manual errors and creates repeatable release procedures. They are operating within a set of disciplines, pre-deployment checks, staged rollouts, structured monitoring, rehearsed rollback plans , that make careless deployments difficult and fast recovery the default.
This is not expensive engineering overhead. It is the infrastructure of reliability, and it pays for itself the first time it prevents a major incident.
Reliability is not only about deployments. It also depends on handling high traffic and concurrent connections efficiently once updates are live.
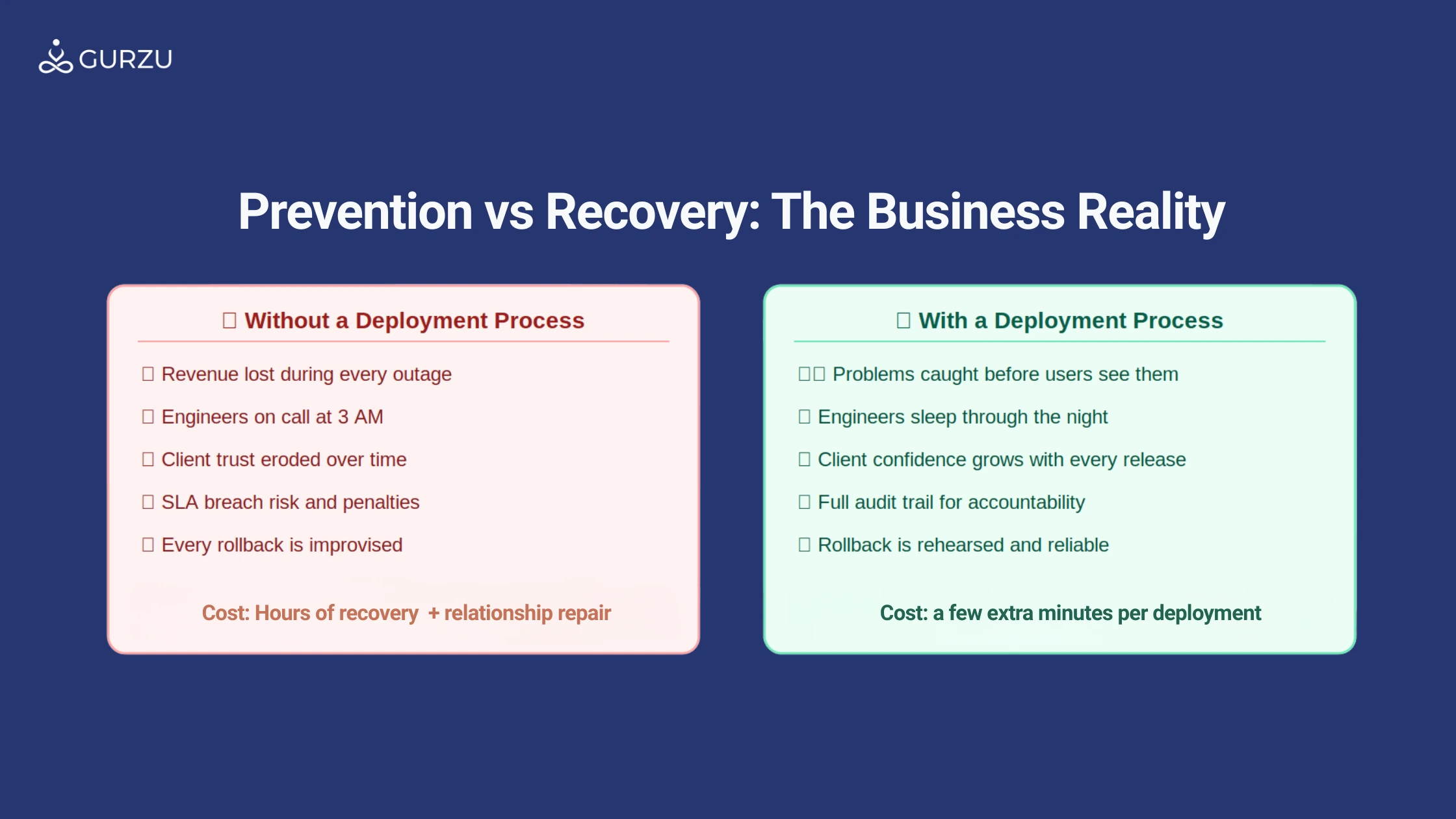
Figure 2: The business reality : prevention costs minutes, recovery costs days
What a Responsible Rails Deployment Process Looks Like?
You do not need to understand the technical implementation to understand the shape of a good process. At a high level, every significant software update should move through four stages before it is considered complete.
Check before anyone sees it. Before a single line of new code reaches any user, it passes through automated safety checks, security scans, performance comparisons, compatibility tests. Problems caught here cost minutes. Problems that reach production cost hours.
Release to a small group first. Rather than exposing every user to the new version simultaneously, the update initially reaches roughly 5% of users while the rest continue on the stable version. If something goes wrong, only a fraction of users are affected, and the system automatically reverts. This is sometimes called a canary deployment, named after the canaries miners used to detect danger early.
Staged rollouts become significantly easier when applications run on modern containerized deployment infrastructure, allowing teams to control traffic and recover quickly if problems appear.
Watch closely for 24 hours. The most damaging failures, memory leaks, slow database queries, background processing issues, do not announce themselves immediately. Automated monitoring watches specific signals after every deployment. Tools such as application monitoring with Sentry help teams detect issues before users begin reporting them.
Formally close the loop. Once the system has been stable for 24 hours, the deployment is closed. Any issues that arose, however minor, are documented so the process can improve. This is how deployment discipline compounds over time.
The Hidden Cost of an Unmanaged Incident
When a production deployment goes wrong without a structured recovery process, the costs accumulate quickly and across multiple dimensions simultaneously.
Direct revenue loss: if the application is unavailable, transactions cannot complete, bookings cannot be made, and services cannot be delivered. For any business with meaningful digital revenue, an hour of downtime has a quantifiable cost.
Engineering time: an unplanned production incident pulls the entire engineering team into emergency mode. In a typical mid-size company, an incident that lasts three hours might consume forty or fifty engineering hours in total, when all the cross-functional time is counted.
Client and user trust: this is the cost that is hardest to quantify and easiest to underestimate. A client who experiences an outage during a critical business moment does not only count the downtime, they reassess whether the system is reliable enough to depend on.
Compliance and contractual exposure: for businesses operating under service level agreements, an unmanaged incident may trigger breach conditions with financial penalties.
What to Ask Your Engineering Team
You do not need technical expertise to hold your team accountable for deployment quality. These questions are fair to ask of any engineering team, and a team with a mature process will answer them clearly and confidently.
- ‘If something goes wrong with the next update, how quickly can we revert to the previous version, and has that reversion actually been tested?’
- ‘How do we know the update is working correctly four hours after it goes live?’
- ‘What percentage of users receive the update first, and what triggers a full rollout?’
- ‘When was the last deployment incident, and what process change came out of the review?’
These are process questions, not technical ones. The answers reveal whether your team is operating with discipline or with intuition. Both can work, until they do not.
Need Help Keeping Your Rails Application Reliable?
Building a resilient deployment process is only one part of maintaining a healthy Ruby on Rails application. Long-term reliability also depends on proactive maintenance, timely security updates, performance optimization, infrastructure monitoring, and ongoing technical support.
Whether you’re running a growing SaaS platform or a business-critical web application, having an experienced Rails team continuously monitor and maintain your application can significantly reduce downtime, improve performance, and extend the lifespan of your product.
See how our Ruby on Rails Maintenance Service helps businesses keep their Rails applications secure, scalable, and available around the clock with proactive monitoring, timely updates, and expert support.
Concludingly,
Software updates are an unavoidable reality of running a modern digital product. They carry inherent risk, not because developers are careless, but because production systems are complex and the only way to validate that something truly works is to run it in the real world.
As applications grow, deployment discipline becomes even more important alongside techniques for scaling Rails applications and maintaining performance under increasing demand.
The difference between an update that goes smoothly and one that causes an incident is almost never the quality of the code. It is the quality of the process surrounding it.
Pre-deployment checks, staged rollouts, structured monitoring, and rehearsed rollback procedures are not optional luxuries for teams with extra time. They are the infrastructure of reliability.
“Boring deployments are a sign of a healthy engineering culture. Exciting ones are a warning sign.”
This article is the first in a series. Subsequent pieces cover the technical implementation: pre-deployment safety gates, zero-downtime database migrations, canary deployments, and post-deployment monitoring , written for engineering teams responsible for high-availability Rails applications.
